You may remember my previous article about high-performance I/O for cloud databases, where I tested out the Silk Platform and got a single Azure VM to do over 5 GB/s (gigaBytes/s) of I/O for my large database query workload. The magic was in using iSCSI over the switched cloud compute network to multiple “data VMs” at the virtualized storage layer for high I/O throughput and scalability.
Well, the Silk folks are at it again and Chris Buckel (@flashdba) just sent me screenshots of similar test runs using the latest Azure “v5” instance as the single large database node and they achieved over 10 GB/s scanning rate for reads and 6 GB/s write rate with large I/Os!
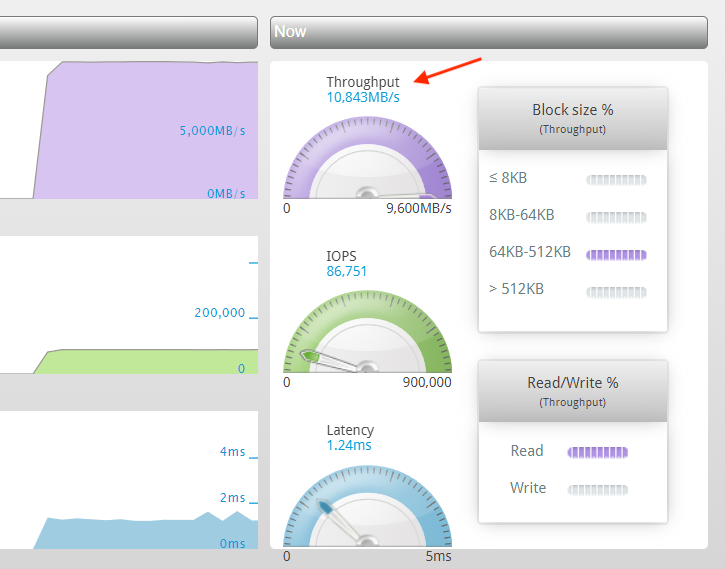
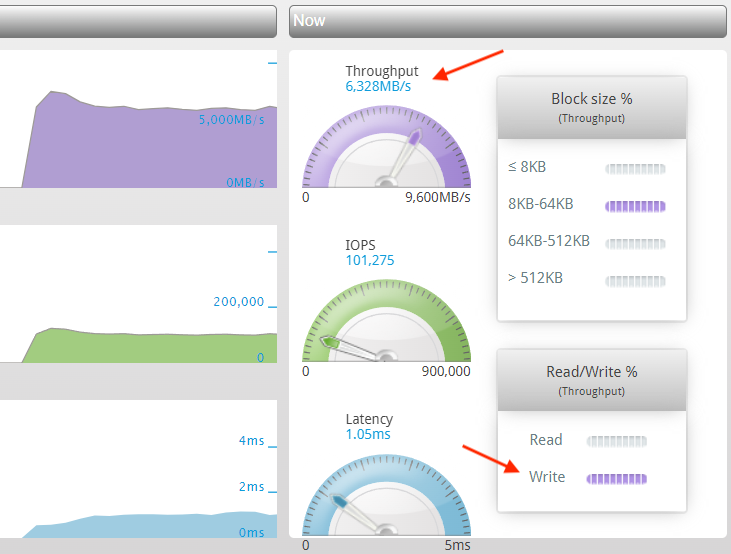
The performance geek in me was pretty excited to see that it’s even possible to get such performance in a single cloud VM, so I thought to write a blog entry. You can read how this is architecturally possible from my past blog entries:
- Achieving 11M IOPS & 66 GB/s IO on a Single ThreadRipper Workstation
- Testing The Silk Platform - Hands-On Technical Analysis of High-Performance I/O in the Cloud
Both articles are pretty long, so here’s a short summary of keywords that cover which hardware, software and architectural developments make this possible in modern cloud environments:
Disks & CPUs
- Directly attached NVMe flash SSD disks
- PCIe 4.0 (and PCIe 5.0) with high bandwidth per lane
- CPUs with many PCIe lanes
- 128 PCIe 4.0 lanes per CPU socket would give 2 terabit/s aggregate PCIe-CPU bandwidth in each direction!
- NVMe + PCIe essentially expose the flash disk controller memory & interface directly to the CPU (accessed via DMA memory reads/writes)
- Thanks to NVMe protocol, no SCSI or Fibre Channel adapters needed in between
This means lower latency and higher throughput for local I/O in a single machine. To scale out and make this I/O capacity accessible to various client machines (like a big database instance), you need to be able to serve those I/Os over the network:
Network
- Cloud vendors already use 400gbit network cards (and switches)
- You can have multiple network cards inserted into each server (minding the PCIe throughput)
- Each network card can have multiple ports (like the cheap 100gbe cards in my lab have 2 ports, giving total aggregate throughput of 200gb/s in both directions)
- 800 gbe and 1.6 Tbe cards are coming next :-)
- At such data rate, you don’t want your CPUs to be handling each network packet individually
- Modern network cards support various offloading like TCP checksum offloading, interrupt coalescing, large send/receive offloading, etc.
Cloud & Virtualization
- Modern hypervisors, together with NIC vendor drivers, expose these offloading capabilities to VMs
- Azure has “accelerated networking” for this purpose, AWS has the Nitro chips & drivers
- You need to make sure that this feature is enabled for your VM (and instance type) and actually visible/used at the OS level
- Measuring interrupt rates (and interrupt CPU usage) vs packet rates is one starting point
Summary
If a database is scanning data at 10 GB/s, a single 400gbe link in an Azure v5 host machine would be only 25% utilized (in one direction). I actually don’t know if these instance types use 400gbe yet (or just dual-port 200gbe cards), but that’s not too relevant here. My point is that such I/O rates even for a single, monolithic database are not only possible, but not even such a big deal anymore, given how fast the modern (network) hardware is!
You just need to make sure that you don’t have bigger bottlenecks elsewhere in your I/O topology, avoid legacy technologies (like some fibre-channel HBAs + SAN networks) and of course make sure that your solution is reliable enough, so you won’t lose or corrupt your data (this is also done in the software nowadays).
Upcoming webinar
I have something to promote too! (Who would have guessed that? ;-)
We are holding a technical & architectural discussion with Kellyn Gorman (of Azure) on December 8, 2021. This won’t be a rehearsed presentation, but more of a free-form discussion where I’ll ask some questions from Kellyn and drop in my opinions as well.
Should be fun, so see you there!
