Here’s a little PL/SQL function create_partition_high_value_func.sql that allows you to write SQL queries against data dictionary for partition maintenance automation and examination operations, by converting the cumbersome LONG-datatype to VARCHAR2 on the fly. This approach works also on Oracle 19c and earlier versions.
It runs a nested SQL query inside PL/SQL for every (owner, table, partition_name) tuple that your SQL passes into the function. This is normally not a good practice for performance, but due to the LONG restrictions, there are no other “pure SQL” options to work around this for a single SQL statement. Even Oracle 23ai uses a similar PL/SQL function approach under the hood for its new HIGH_VALUE_CLOB and HIGH_VALUE_JSON fields in *_TAB_PARTITIONS views (more about this below).
You do have to create this stored PL/SQL function first:
SQL> @tools/create_partition_high_value_func.sql
Function created.
And then you can use it in regular SQL statements, joins, aggregations and things like SUBSTR() calls, without hitting the ORA-00997: illegal use of LONG datatype errors. One example is to find the latest partition (with highest partition_position value) and its high value for each partitioned table in a schema:
SQL> SELECT
2 table_owner
3 , table_name
4 , partition_name
5 , get_partition_high_value(table_owner,table_name,partition_name) high_value_char
6 FROM
7 all_tab_partitions
8 WHERE
9 (table_owner, table_name, partition_position) IN (
10 SELECT table_owner, table_name, MAX(partition_position)
11 FROM all_tab_partitions
12 WHERE table_owner = 'SH'
13 GROUP BY table_owner, table_name
14* )
SQL> /
OWNER TABLE_NAME PARTITION_NAME HIGH_VALUE_CHAR
------ ---------- --------------- ---------------------------------------------------------
SH SALES SYS_P14960 TO_DATE(' 2013-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS')
My schema has just one partitioned table in this case, but with more tables you’d see one line of output per partitioned table.
The query above is just a simple generic example, you’d have to write correct queries matching what you’re trying to achieve. Things like monitoring, examining partition value ranges regardless of what the partition name claims, verifying data ranges in a partition before dropping it by its name and creating new (range) partitions based on the current latest partition definition. This all was already possible when using checks in PL/SQL loops and other scripting languages, just putting it all into a SQL query was a problem due to the LONG datatype.
Inlining PL/SQL code directly into SQL?
Can we just put this PL/SQL code into the SQL WITH clause (from 12c onwards) and avoid creating a stored function?
Yes we can!
WITH
FUNCTION get_partition_high_value_inline(
p_owner IN VARCHAR2,
p_table_name IN VARCHAR2,
p_partition_name IN VARCHAR2
) RETURN VARCHAR2
IS
lv_long LONG;
BEGIN
SELECT high_value
INTO lv_long
FROM all_tab_partitions
WHERE table_owner = p_owner
AND table_name = p_table_name
AND partition_name = p_partition_name;
RETURN TO_CHAR(lv_long);
END;
SELECT
table_owner,
table_name,
partition_name,
get_partition_high_value_inline(table_owner, table_name, partition_name) AS high_value_char
FROM
all_tab_partitions
WHERE
(table_owner, table_name, partition_position) IN (
SELECT table_owner, table_name, MAX(partition_position)
FROM all_tab_partitions
WHERE table_owner = 'SYS'
GROUP BY table_owner, table_name
)
AND get_partition_high_value_inline(table_owner, table_name, partition_name) NOT LIKE 'MAXVALUE%'
Here’s a screenshot with some output:
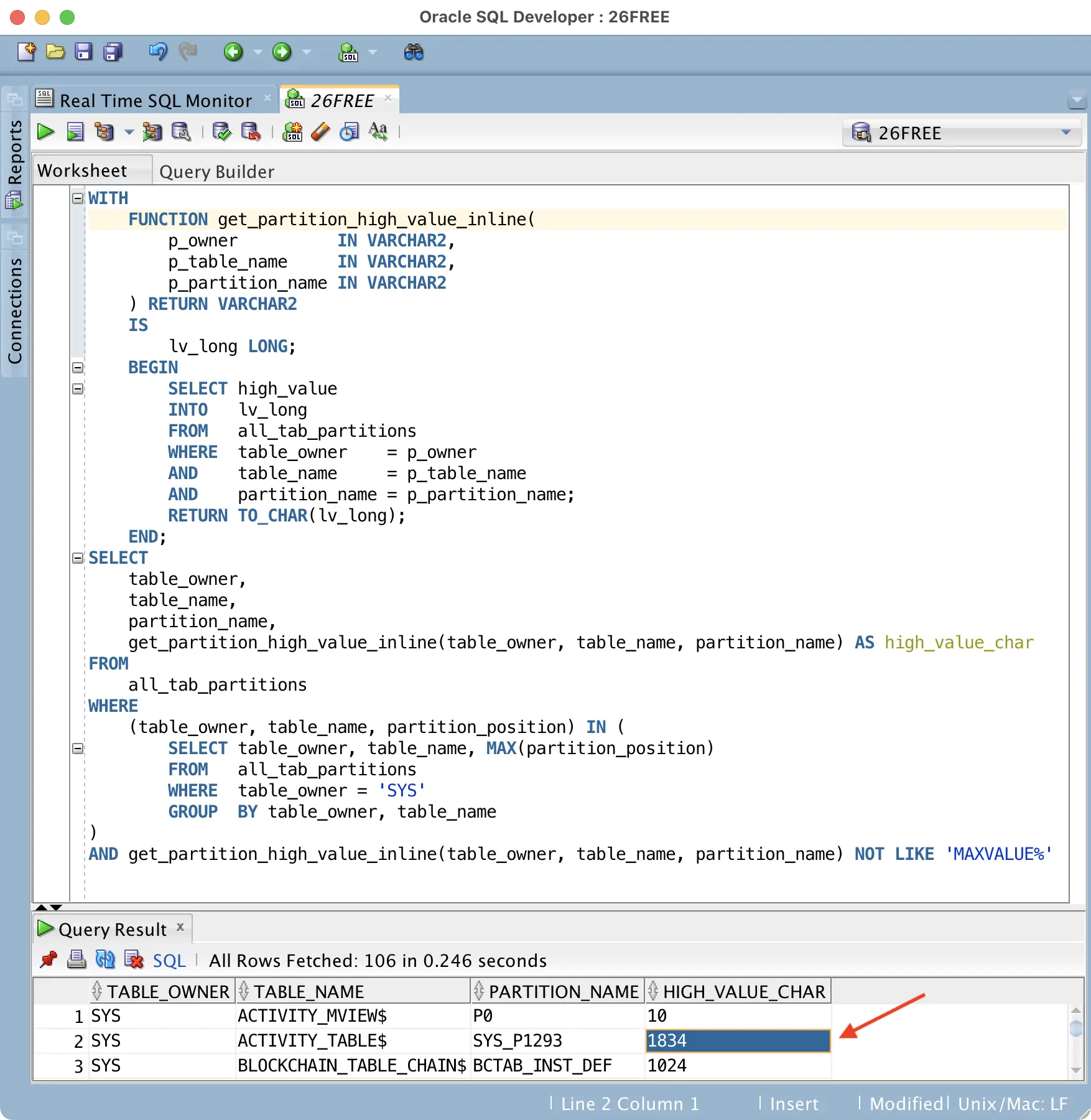
In this case I listed the current highest partition (via MAX(partition_position)) of all partitioned tables in SYS schema that don’t have a MAXVALUE partition. I can see that for the SYS.ACTIVITY_TABLE$, the highest partition has a synthetic name SYS_P1293 and it can accept increasing values up to less than 1834, until the interval partitioning code would automatically create a new interval partition with a new high-value.
SQL> @tabpart ACTIVITY_TABLE$ OWNER TABLE_NAME POS COM PARTITION_NAME NUM_ROWS HIGH_VALUE_RAW -------- ---------------- ---- --- --------------- ---------- -------------- SYS ACTIVITY_TABLE$ 1 NO P0 42 10 SYS ACTIVITY_TABLE$ 2 NO SYS_P312 124 106 SYS ACTIVITY_TABLE$ 3 NO SYS_P313 196 202 ... SYS ACTIVITY_TABLE$ 18 NO SYS_P1165 420 1642 SYS ACTIVITY_TABLE$ 19 NO SYS_P1213 177 1738 SYS ACTIVITY_TABLE$ 20 NO SYS_P1293 1834
The ability to use the partition high-value info just like any other VARCHAR2 field in WHERE clauses, aggregations allows me to write more complex examination & monitoring queries as a single SQL.
Important: I wouldn’t normally be doing things like embedding PL/SQL function calls (that run additional SQL statements under the hood!) into WHERE clauses of SQL queries and not even the projection list.
Embedding PL/SQL function calls in SQL can really hurt your SQL performance as if you scan and filter 1M rows with such a WHERE clause, you’d end up calling this function (and running the SQL in it) a million times! Or if returning only 10k rows from a query, using such a function in the SELECT (projection) list, you’d still call it 10k times.
However, we typically do not process millions of rows when monitoring partitioned tables - and such queries are not executed very frequently all the time anyway. We’d just output a few hundred or a thousand records when doing maintenance ops, so the function in the SQL projection list is not called millions of times. And with carefully-crafted monitoring queries, like my MAX(partition_position) filter pushed down into a subquery above, you can ensure that a SQL plan change does not accidentally end up looping through (and filtering) millions of rows using PL/SQL calls in the WHERE clause.
There’s still a chance that some query unnesting or transformation would end up with the PL/SQL filter in a “too deep” location, you’d want to apply all regular filters first. To avoid that, you could even use a WITH subquery to first build and materialize the list of interesting records and apply the PL/SQL WHERE clause on that materialized dataset in an outer query.
New Oracle 23ai/26ai HIGH_VALUE_CLOB and HIGH_VALUE_JSON columns
Dani Schnider has previously written about these new data dictionary columns in Oracle 23ai+ and with usage examples. So I won’t duplicate this info here.
I did look inside the ALL_TAB_PARTITIONS view text on 26ai and it is using PL/SQL functions in the dbms_part_internal package for achieving a similar result. It returns a CLOB or JSON only, which however limits/complicates usage of these fields inside more complex monitoring SQLs. So my function may be useful to you even on Oracle 23ai+.
Here’s an excerpt from ALL_TAB_PARTITIONS where the new columns are extracted, indeed a similar PL/SQL function call trick is used:
SQL> @v ALL_TAB_PARTITIONS
Show SQL text of views matching "%ALL_TAB_PARTITIONS%"...
...
dbms_part_internal.get_high_value_clob('TCP', tcp.rowid),
json(dbms_part_internal.get_high_value_json
('TCP', tcp.bo#, tcp.flags, tcp.bhiboundval)),
tcp.chunkid /* chunk id for sharded tables */
from obj$ o, tabcompart$ tcp, ts$ ts, user$ u, tab$ t, imsvc$ svc
where
...
These PL/SQL functions do not accept a tuple of (owner,table_name,partition_name), but accept a ROWID of tabcompart$ base table to fetch the exact record without any index lookups (if you know how to unwrap PL/SQL code, you’ll see how it’s done). :^)
My “userspace” function can not use the ROWID lookup directly as I’m querying standard data dictionary views, not SYS base tables. However, the lookup of a single exact owner/table/partition_name combo is efficient enough with data dictionary indexes too.
