Last year, I published a simple demo app that visualizes embedding vectors of a bunch of cat, dog and airplane photos as heatmaps. It’s a simple concept and does not have much practical use. I built it mostly for fun, but also for some “learning by doing” too.
Today I’m releasing a completely new version of my CatBench Vector Search Playground app!
With this new app, you can interactively navigate through multiple Postgres-based vector similarity search examples and immediately see which SQL statements were executed in the backend and their execution plans with performance metrics. All this is visible right in the web app itself as you explore around. No need to switch to searching through Postgres logs or manually rerunning explain plan for some query in a different tool.
For example, if you pick a cat image from the web app gallery, it performs a vector similarity search using a Postgres SQL query. In addition to the application output, CatBench shows you both the SQL queries used for generating this result and their execution plans with performance metrics:

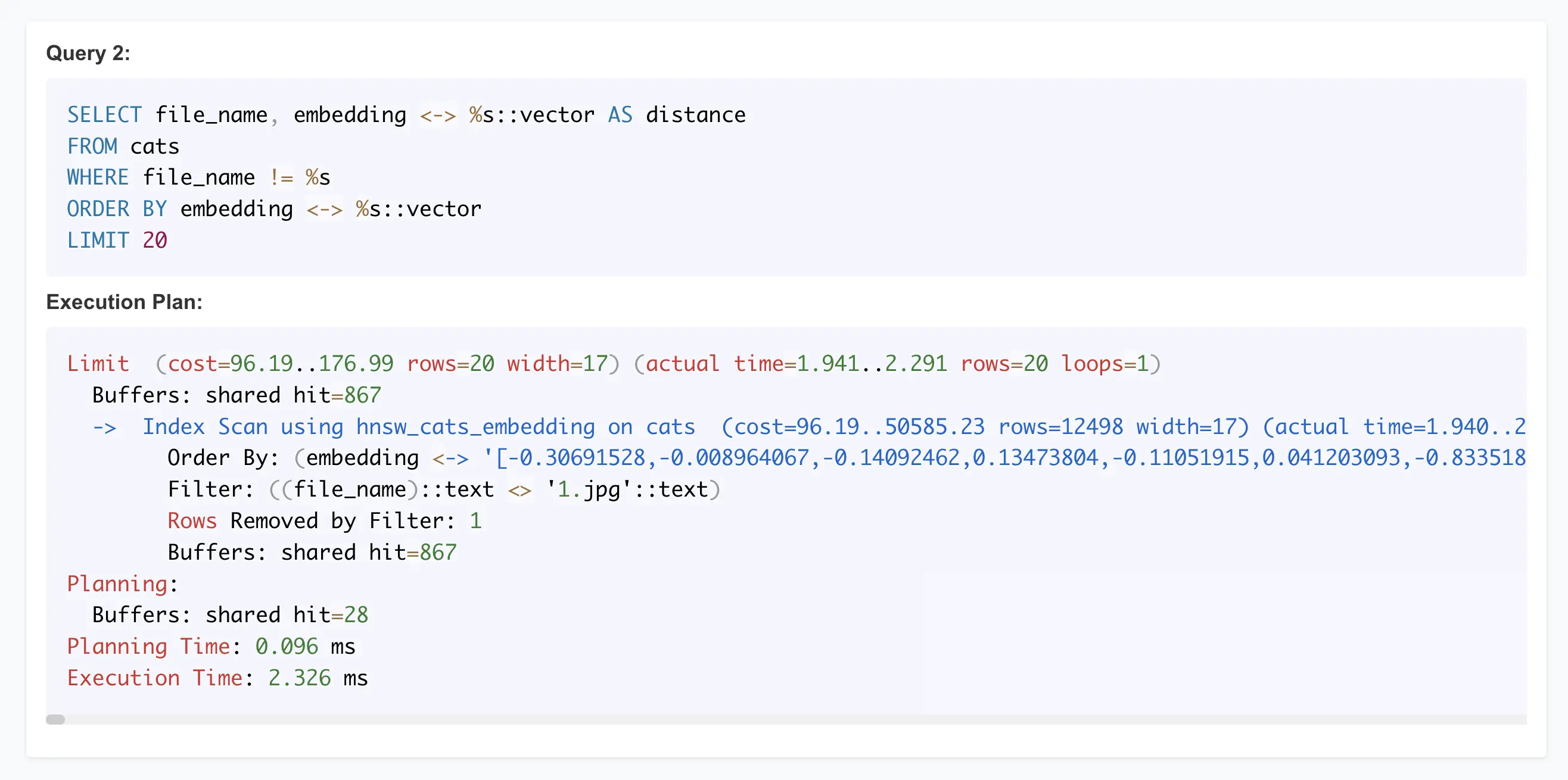
This makes exploring the performance characteristics of such application queries easier, as you can just navigate around or refresh the current browser page after making some changes, like changing the SQL text or creating a different (vector) index.
This is the entire point and philosophy of my work on this application. I want to make exploring application performance easy. This investment will pay off as you can iterate through your performance experiments faster, with fewer boring, repetitive tasks in between.
I have enhanced the OLTP schema (HammerDB TPC-C) with a simple recommendation engine use case by adding two more tables (customer_fingerprints for the AI similarity search and pre-computed customer_top_items for quick lookups of top-ranked product purchases by each customer.
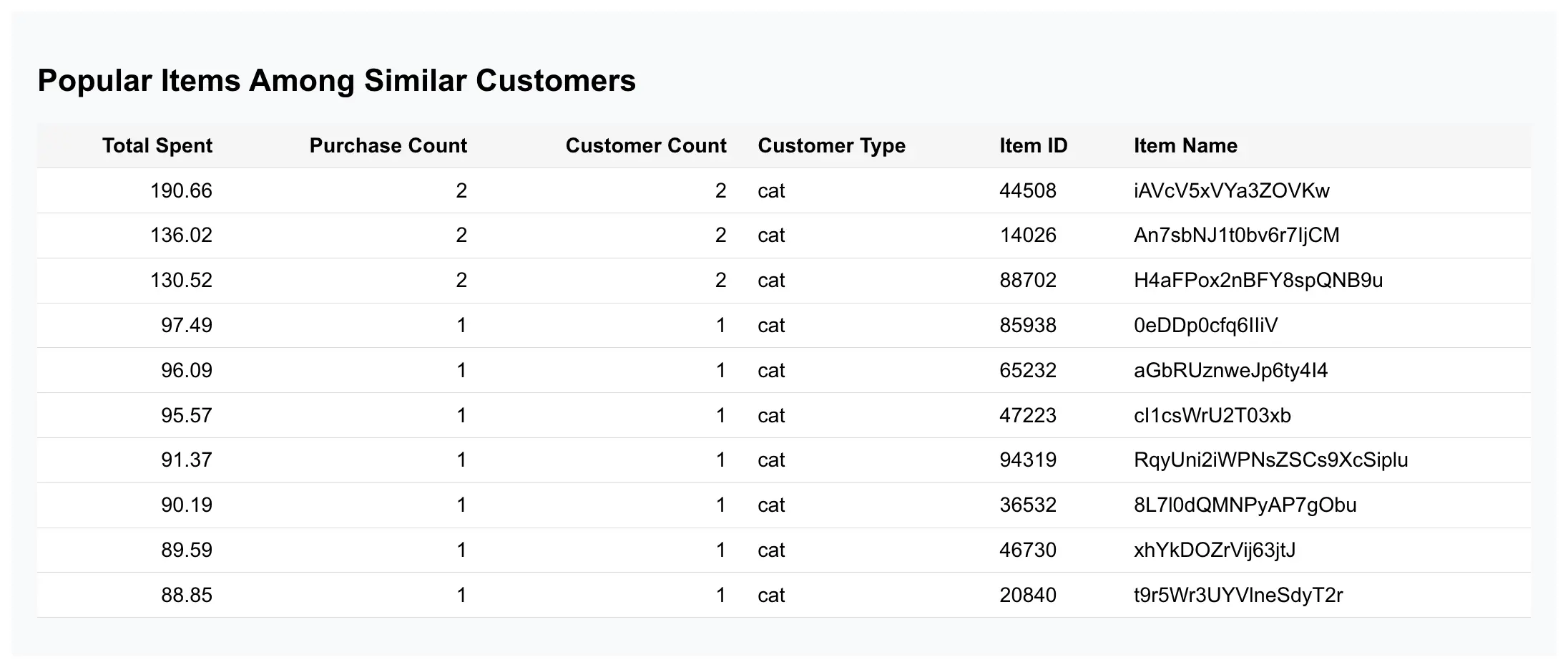
This is where we connect the worlds of regular transaction data (order history) and the AI-assisted customer similarity search. Due to how the (approximate) nearest neighbor search works, I want the vector search on customer_fingerprints to be executed only once and let its results drive the rest of my query. During the CatBench setup steps, you’d also precompute a (daily?) summary of each customer’s top purchases into the customer_top_items table. This avoids complex multi-table joins in the TPC-C schema when displaying personalized recommendations to each visitor of your online store.
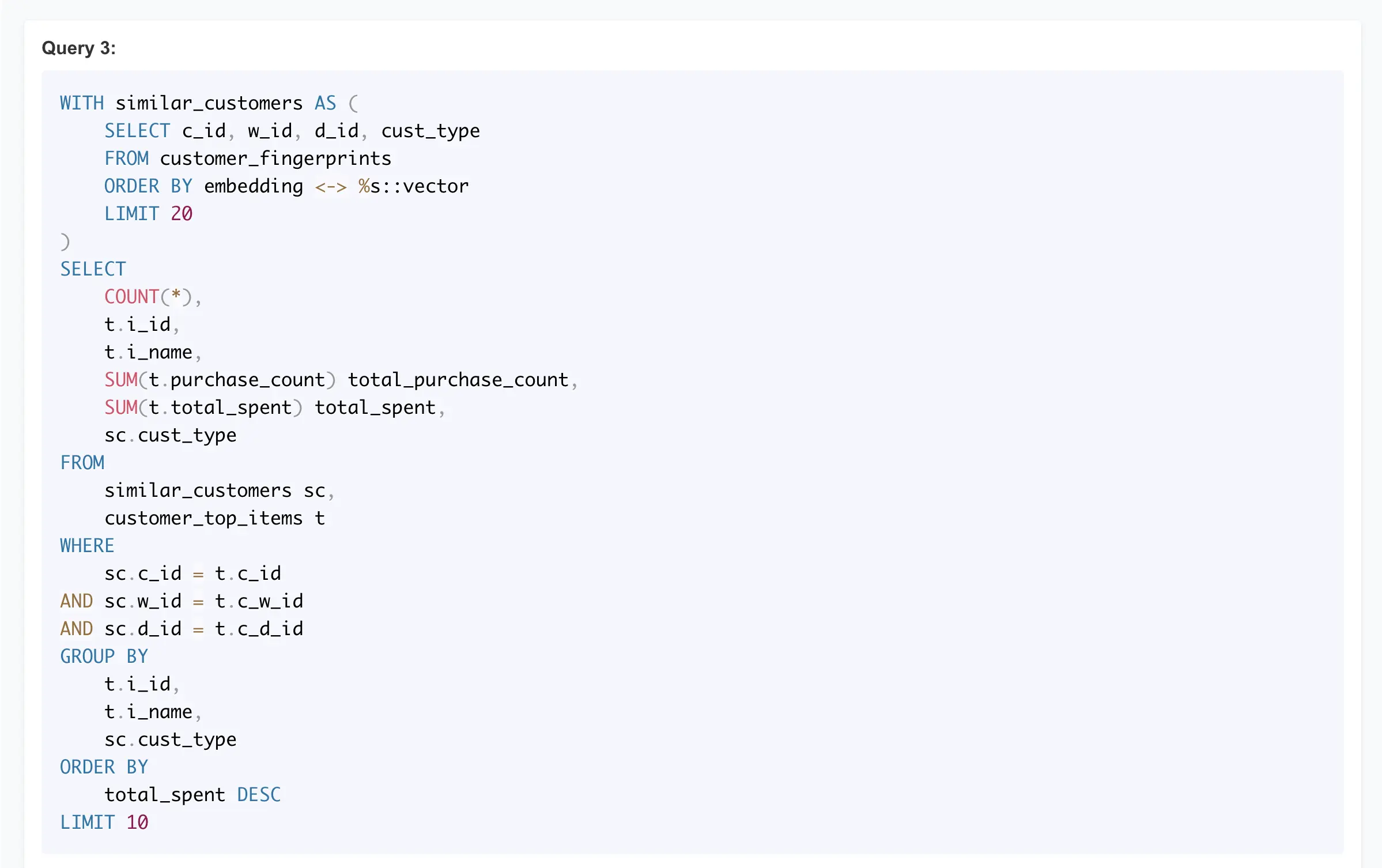
Here’s the execution plan that first uses the hnsw_cust_fp_embedding HNSW vector index on customer_fingerprints table for finding top 20 most similar-looking cats (look for the “deepest” areas in the plan output that are indented the most). And the rest of the query plan uses these rows for finding matching top purchases and aggregating results, etc.

That’s all! In the next version I’ll add Postgres database-wide throughput monitoring of all activity (including vector search queries), so we’d have some nice charts to look at - stay tuned!
Summary
I recently wrote an article about a similar example of AI-enhancing your existing applications with vector search on Silk Platform, with some more details about the database schema layout changes. If you like the CatBench app so far, you can get it from GitHub and try it out yourself!
