I hereby announce that I will retire in 2030 and replace myself with a computer!
I am serious. This is probably the clearest mission statement I’ve ever come up with in my career! This is essentially my statement of direction for the next 10 years. There will be a series of posts about what I am up to and where I’m going.
My plan for the next 10 years
When the year 2020 arrived, I spent a month thinking about the future and what I want to be working on for the next decade. I even spent a week in an isolated cabin in Colorado mountains, reading and thinking. I reached the conclusion that (my) future will hold a lot of computer system and human interaction automation (read: humans won’t be needed… ahem… as much). This is actually a good thing, it will make our life easier and allow us humans work on more interesting and valuable things. Also, you’ll be able to build & run apps for your business much faster, with less trouble, magically and automatically ;-)
I am talking about machine learning-assisted improvement of software development, operations, application reliability and performance optimization processes. For some parts of the process I’ll build just semi-automated helper tools, but some parts will eventually be completely automated. Remember, I’m talking about my 10 year direction, I will definitely start from shipping simpler stuff and increase ambition as I go. Nevertheless, I do want to go way beyond what I call “manual automation”. The eventual system should be intelligent enough and able to adapt, improve and optimize itself towards its goals, regardless of the target application.
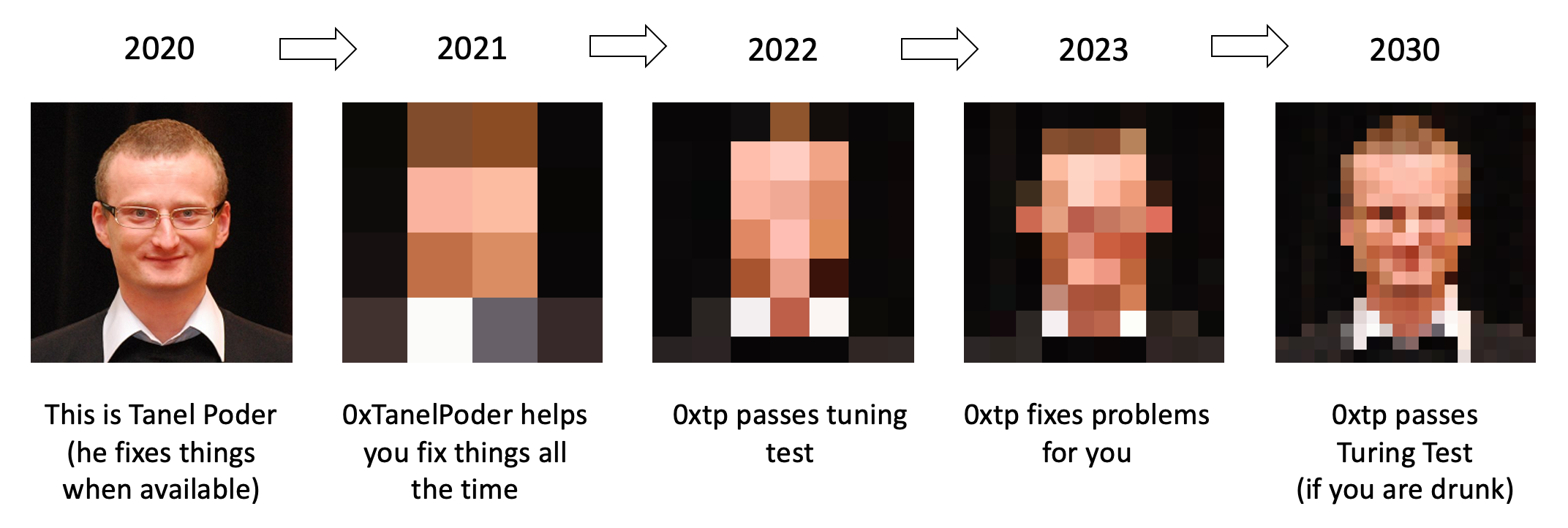
Wait, what?
In short, I don’t intend to keep “manually” doing the same work over again for the next 10 years. For example, a common pattern I repeat as a performance & troubleshooting consultant is about getting the right diagnostic data at the right detail level for systematically troubleshooting a problem. But with the right data readily available, there’s no need for “advanced expert guessing” and troubleshooting becomes predictable and easy. For truly complex scenarios, depending on where the initial analysis had pointed to, we had often put additional data collection or tracing in place and soon the root cause became clear. This kind of reasoning and intelligent “treasure hunt” of next clues should be automatic too.
So, you need the right data at the right time and a systematic way of thinking about it when troubleshooting any application’s reliability, efficiency or performance problems.
I plan to automate problem solving
I plan to automate everything mentioned above and as an outcome, you’ll have:
- Automatic, adaptive, relevant diagnostic data collection for any application
- Automated problem detection, troubleshooting and improvement recommendations
- Basically everything that I currently do as a consultant, but available 24x7 and on steroids
- I will replace myself with an intelligent, observing and learning system, AI Tanel Poder if you will
- I will call it
0xTanelPoderfrom now on (0xtpin short and yes, there’s anoxtp.com domain for the future(changed my plans regarding the domain name).
I will document the journey and invite you to be a part of it
To make this a reality, I will need to learn a lot myself. Will need to go deep into machine learning. And I don’t mean just integrating ML tools & models downloaded from Internet, but building whatever is missing from ground up myself, all the way to algorithm level, if needed. This will be a multi-year effort.
- I consider the relevant data extraction to be an easy task compared to the other things ahead
- The AI
0xTanelPoderpart is the hardest part and most of my R&D will be done on that over the years - It’s not going to be easy to replace me with AI, because of course I am very smart. At the same time me being very smart will make it easy for me to replace mysel☐☐ᅟ°∞Segmentation Fault (Core Dumped)
- Don’t take the previous claim too seriously (still beta)
- The delivery model will be an open source data collector + SaaS backend
This requires me to find and evaluate suitable cloud backend components that get the job done — with minimum cost and administrative overhead. I don’t want to spend any time on installing databases, scaling clusters or “provisioning stuff”. The architecture needs to be dead simple and mostly “serverless” likely.
The last statement may come as a surprise to my followers with traditional enterprise IT background (like myself). Other than the long term ML ambitions, I hope that these “flat and easy cloud architecture” lessons learned will be useful for a lot of my followers too, having the future in mind. If your daily work is mostly about manually installing software, provisioning databases and moving around datafiles, then your job is at risk! Self-service and managed cloud platforms keep taking over even in traditional enterprises. At startups and smaller projects, there are good reasons to use self-service “XaaS” and serverless technologies if you want to move fast, without needing an entire team of people to manually (read: slowly) manage “the stack” used by just a couple of developers.
I plan to document my journey in the form of blog entries, online hacking sessions and tweets explaining my reasoning, design decisions and lessons learned. I think I’ll call this experience Tanel Poder’s Underground University and will self-deal myself a PhD degree in computer science before I boot up the final human-written release of 0xTanelPoder in 2030 and we all can retire for good.
What’s next?
If you are interested in this journey, then just subscribe to my tweets or mailing list below and you’ll be the first to get the news!
-
Follow me in Twitter:
Follow @TanelPoder -
Contact/join mailing list:
0xTanel Poder
Update 1: Half a day after announcing my plans, I saw a paper published by Microsoft Research, coming to similar conclusions as I posted here. Good timing and great to see others exploring this as well! Another example of some of these ideas already in action is the Amazon’s CodeGuru service (in preview). In other words if you believe that none of this can be done, some of it has already been done!
